
The magic of super-resolution: Insights from our latest research
October 14, 2024 | 3 min readBy: Marine Sorin, Senior Product Manager and Nelson Francisco, Principal Video Compression Engineer
We’re thrilled to once again highlight the groundbreaking work of our innovation team. After optimizing the compression of stored video, they’ve now turned their attention to the fascinating world of upscaled images. Just last week, they were at MMSP 2024 to present their latest advancements.
What is super-resolution?
Imagine you’re looking at a blurry, low-resolution image, and suddenly it transforms into a sharp, high-resolution one. This “magic” happens thanks to a process called super-resolution (SR)1, which uses advanced algorithms to enhance low-quality images or videos. Early SR methods relied on simple tricks2 like zooming in and smoothing out pixels, but today’s approaches are far more sophisticated.
In this post, we’re giving you a peek behind the curtain of our cutting-edge research. Whether you’re a tech enthusiast or simply curious about the future of multimedia, you’re in the right place.
The game-changer: deep learning
The real breakthrough in super-resolution came with the introduction of deep learning (DL)3, particularly through convolutional neural networks (CNNs)4. Early methods often struggled to create clear images, leading to smooth but blurry results. Deep learning changed the game, allowing machines to “learn” how to fill in missing details by analyzing large datasets of images.
How does it work?
For training, the engine is shown a vast number of paired low-resolution and high-resolution images. The engine compares the generated high-resolution image to the original, measuring how accurate it is using a loss function. The goal? Minimize the difference and teach the engine to predict the high-resolution version from the low-resolution input.
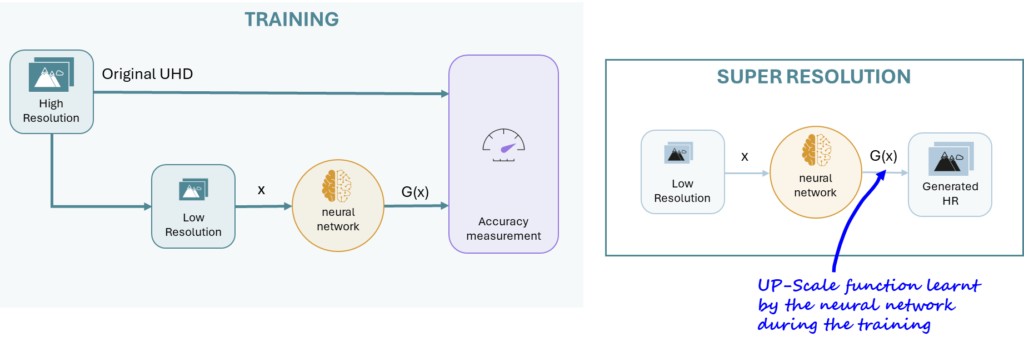
CNNs are specialized deep learning models designed for processing images. They work like layers of filters, each refining the image further until it becomes clear. However, there’s a catch—CNNs often produce smooth, less detailed results because the loss functions they rely on tend to average things out, making the images too smooth.
Enter GANs: a smarter solution
Generative Adversarial Networks (GANs)5 are a more advanced approach to super-resolution. Unlike CNNs, GANs use two neural networks working together:
- The Generator: Creates the upscaled image.
- The Discriminator: Tries to determine whether the upscaled image is real or fake by comparing it to the original high-resolution image.
These networks engage in a “game” where the generator attempts to fool the discriminator. Over time, this competition forces the generator to produce sharper, more realistic images.
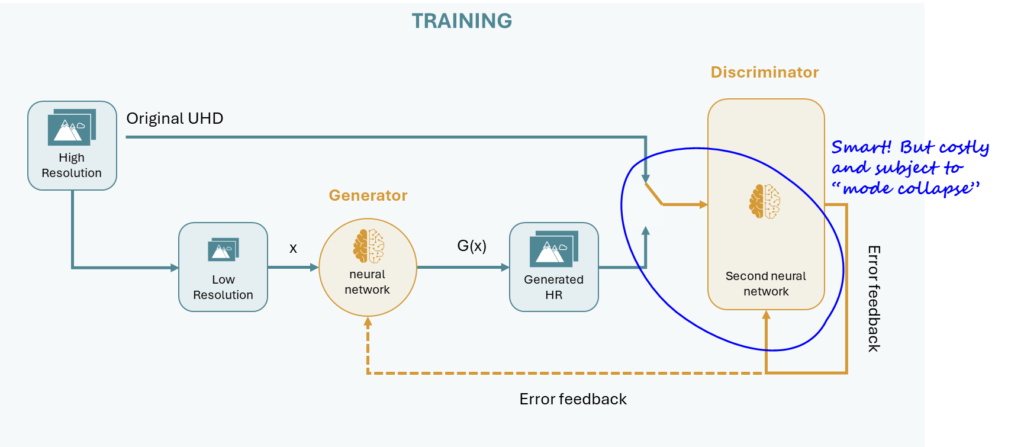
However, GANs aren’t perfect. They can sometimes get stuck generating repetitive images (a phenomenon known as mode collapse6) or produce strange visual artifacts. To overcome these challenges, researchers tweak the training process, adjusting parameters and adding regularization to keep things on track.
Our new approach: residual super-resolution
Our team has developed an innovative method by enhancing an existing model called ESRGAN7. Instead of having the engine transform the entire image, our approach focuses on learning an enhancement residue that is added to a base reconstruction. In simple terms, it’s like placing a “refinement layer” over the original image to sharpen the details.
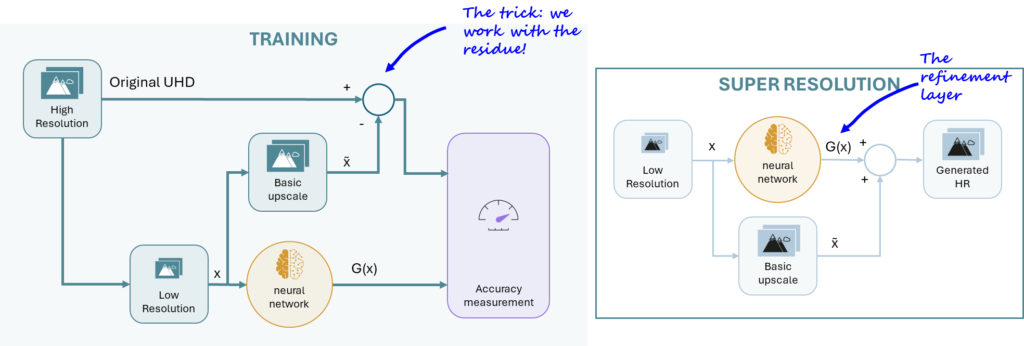
This technique not only minimizes the risk of mode collapse but also generates sharper, more realistic images. What’s even better? It uses less computational power, making it far more efficient than many of today’s leading methods. And of course, we can’t talk super-resolution without a visual example—take a look at the details of Chambord castle! With such spectacular architecture, every detail matters.

The future of image upscaling
Super-resolution is one of the most exciting areas of AI research, transforming blurry images into sharp, high-definition ones. While earlier techniques had their limits, deep learning—and especially GANs—have pushed the boundaries of what’s possible. And with continuous advancements, we’re getting closer to producing flawless high-resolution images with less effort and greater accuracy.
References
- [1] S. C. Park, M. K. Park, and M. G. Kang, “Super-resolution image reconstruction: a technical overview,” IEEE Signal Processing Magazine, vol. 20, no. 3, pp. 21–36, 2003. ↩︎
- [2] C. Duchon, “Lanczos filtering in one and two dimensions,” Journal of Applied Meteorology, vol. 18, pp. 1016–1022, 08 1979. ↩︎
- [3] J. Schmidhuber, “Deep learning in neural networks: An overview,” Neural Networks, vol. 61, pp. 85–117, jan 2015. ↩︎
- [4] C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, 12 2014. ↩︎
- [5] I. Goodfellow et al., “Generative adversarial networks,” Commun. ACM, vol. 63, no. 11, pp. 139–144, oct 2020. ↩︎
- [6] S. Ravuri and O. Vinyals, Classification Accuracy Score for Conditional Generative Models, Curran Associates Inc., Red Hook, NY, USA, 2019. ↩︎
- [7] X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao, and C. C. Loy, “ESRGAN: Enhanced super-resolution generative adversarial networks,” in Computer Vision – ECCV 2018 Workshops, Cham, 2019, pp. 63–79, Springer. ↩︎
- [8] R. Timofte et al., “NTIRE 2018 challenge on single image superresolution: Methods and results,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 965–96511. ↩︎


